Wir haben eine Liste von 36 kostenlosen und kostenpflichtigen Alternativen zu DiffBot zusammengestellt. Zu den Hauptkonkurrenten gehören UI.Vision Kantu, dexi.io. Neben diesen vergleichen Benutzer auch DiffBot mit Octoparse, import.io, Portia. Außerdem können Sie hier auch andere ähnliche Optionen ansehen: Entwicklungs-Tools.
Wir haben eine Liste von 36 kostenlosen und kostenpflichtigen Alternativen zu DiffBot zusammengestellt. Zu den Hauptkonkurrenten gehören UI.Vision Kantu, dexi.io. Neben diesen vergleichen Benutzer auch DiffBot mit Octoparse, import.io, Portia. Außerdem können Sie hier auch andere ähnliche Optionen ansehen: Entwicklungs-Tools.
Wir konzentrieren uns ausschließlich darauf, Ihnen bessere Webdaten zu liefern. Einige der Gründe, warum Hunderte von Kunden (Hunderte von) Millionen Anrufe pro Monat tätigen:
#Der beste Content-Extraktor im Web:
Diffbot funktioniert automatisch - ohne Regeln oder Training. Es gibt keine bessere Möglichkeit, Daten von Webseiten zu extrahieren. Sehen Sie, wie Diffbot mit anderen Methoden zur Inhaltsextraktion mithalten kann: Funktionsvergleich Text-Extraktionsqualitäts-Shootout
#Seiten automatisch identifizieren:
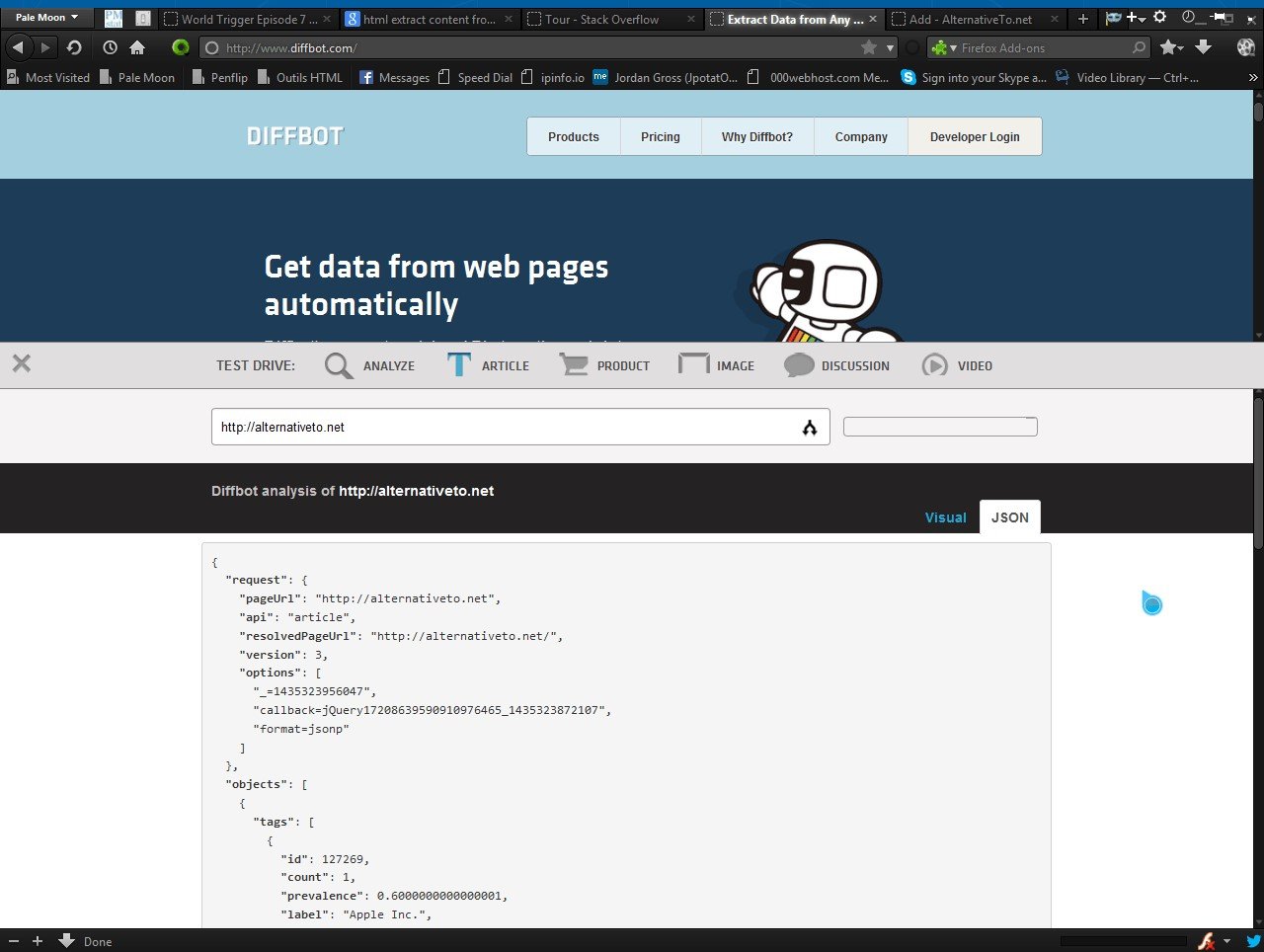
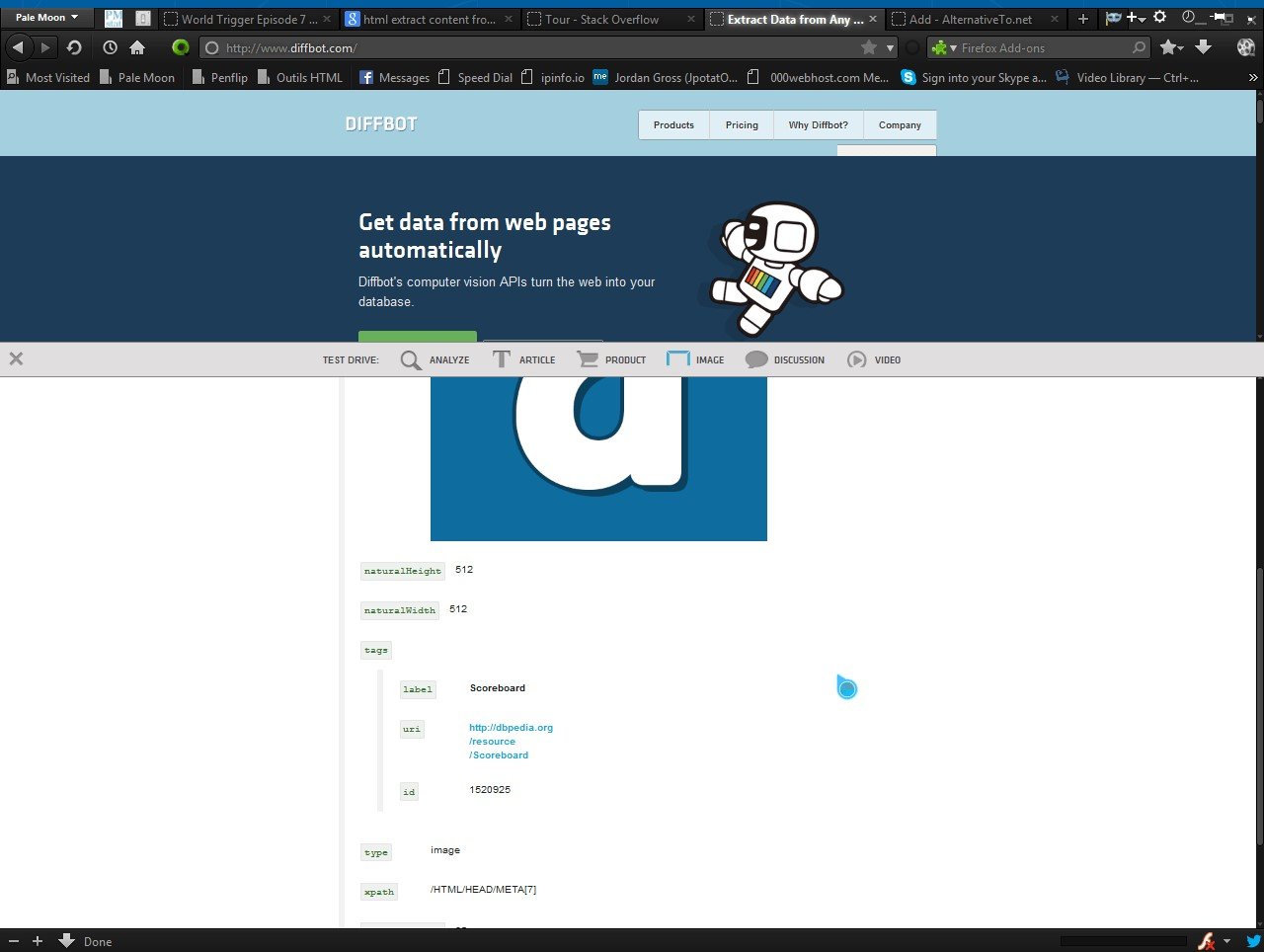
Verwenden Sie die Analyse-API, um automatisch alle Produkte, Artikel, Diskussionen oder Bilder zu finden und zu extrahieren, während Sie eine Site crawlen. API analysieren
# Detaillierte Produktdaten:
Die Produkt-API gibt automatisch vollständige Produktinformationen zurück, einschließlich aller Preisdaten, Produkt-IDs, Marken- und vollständiger Spezifikationstabellen. Produkt-API
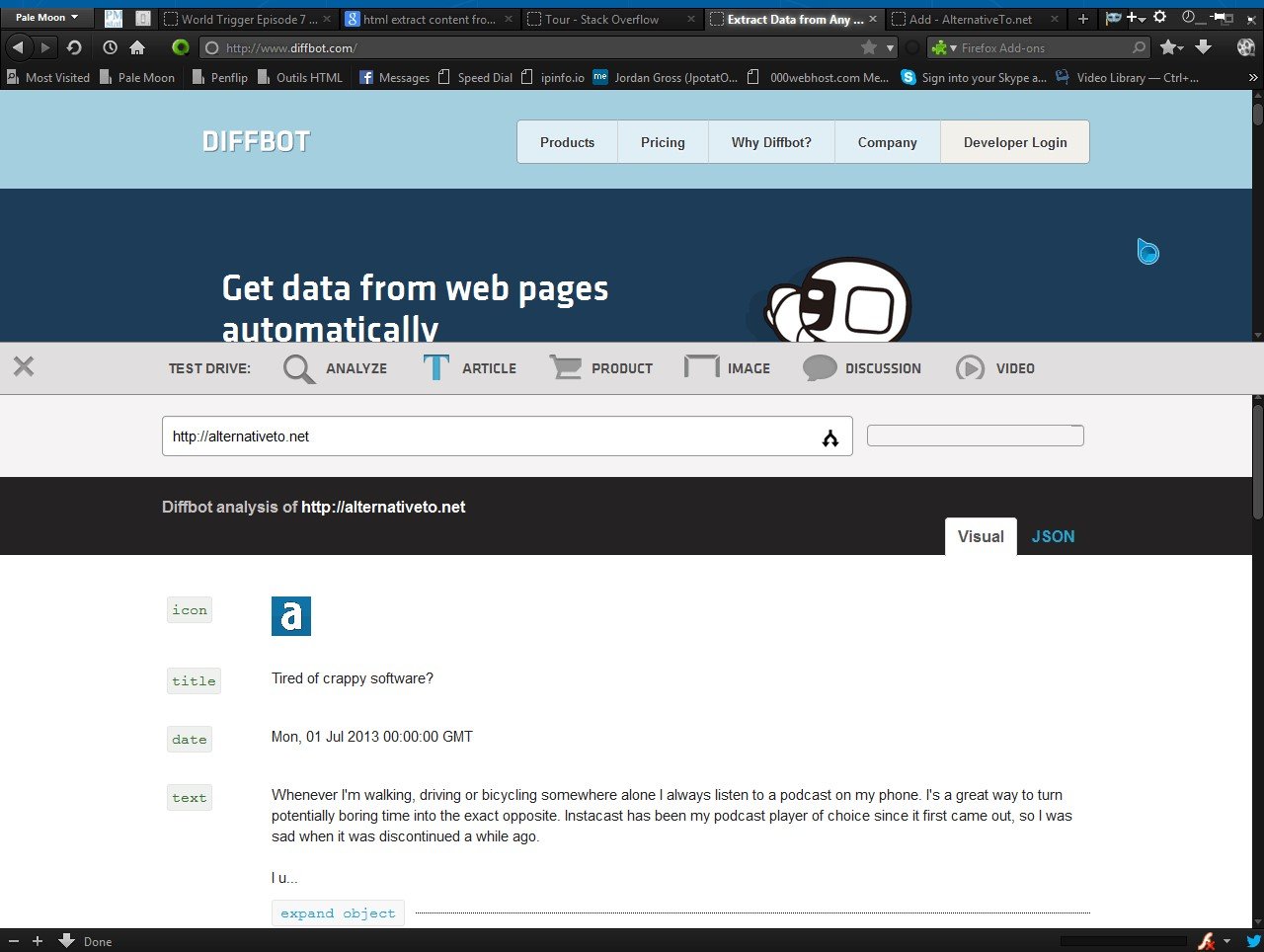
#Clean Text und HTML:
Artikel, Diskussionsthreads, Produktbeschreibungen und Bildunterschriften werden in reinem Text und bereinigtem HTML zurückgegeben. Beginnen Sie noch heute mit dem Testen
#Strukturierte Suche:
Durchsuchen Sie strukturierte Inhalte von beliebigen Crawlvorgängen mithilfe unserer Such-API und geben Sie nur die übereinstimmenden Ergebnisse zurück.
Plus...
¤ Alle APIs führen Javascript aus, sodass der Inhalt wie ein normaler Browser analysiert wird. ¤ Funktioniert dank visueller Verarbeitung auf den meisten nicht-englischen Seiten. ¤ Datumsnormalisierung: Datenstempel werden normalisiert und im Standardformat RFC 1123 (HTTP / 1.1) dargestellt. ¤ Mehrseitige Artikel werden automatisch in einer einzigen API-Antwort zusammengefügt. ¤ Entitätsextraktion: Automatische Kennzeichnung identifiziert wichtige Themen und Entitäten im Artikeltext. ¤ Beheben Sie Probleme in Echtzeit mit dem API Toolkit. ¤ Bulk-API ermöglicht das Extrahieren von Hunderten bis Hunderttausenden von Seiten. ¤ Greifen Sie auf Crawlbot- und Massenjobdaten im vollständigen JSON- oder CSV-Format zu. ¤ Optionales Crawlen mit einem vielfältigen Array von IP-Adressen.