* Automatyczne pobieranie danych ze stron internetowych:
* Automatyczne pobieranie danych ze stron internetowych:
DiffBot Platformy
Web-Based
DiffBot Wideo i zrzuty ekranu
DiffBot Przegląd
Dlaczego Diffbot?
Koncentrujemy się wyłącznie na zapewnieniu lepszych danych internetowych. Niektóre z powodów, dla których setki klientów wykonują (setki) milionów połączeń każdego miesiąca:
# Najlepszy ekstraktor treści w sieci:
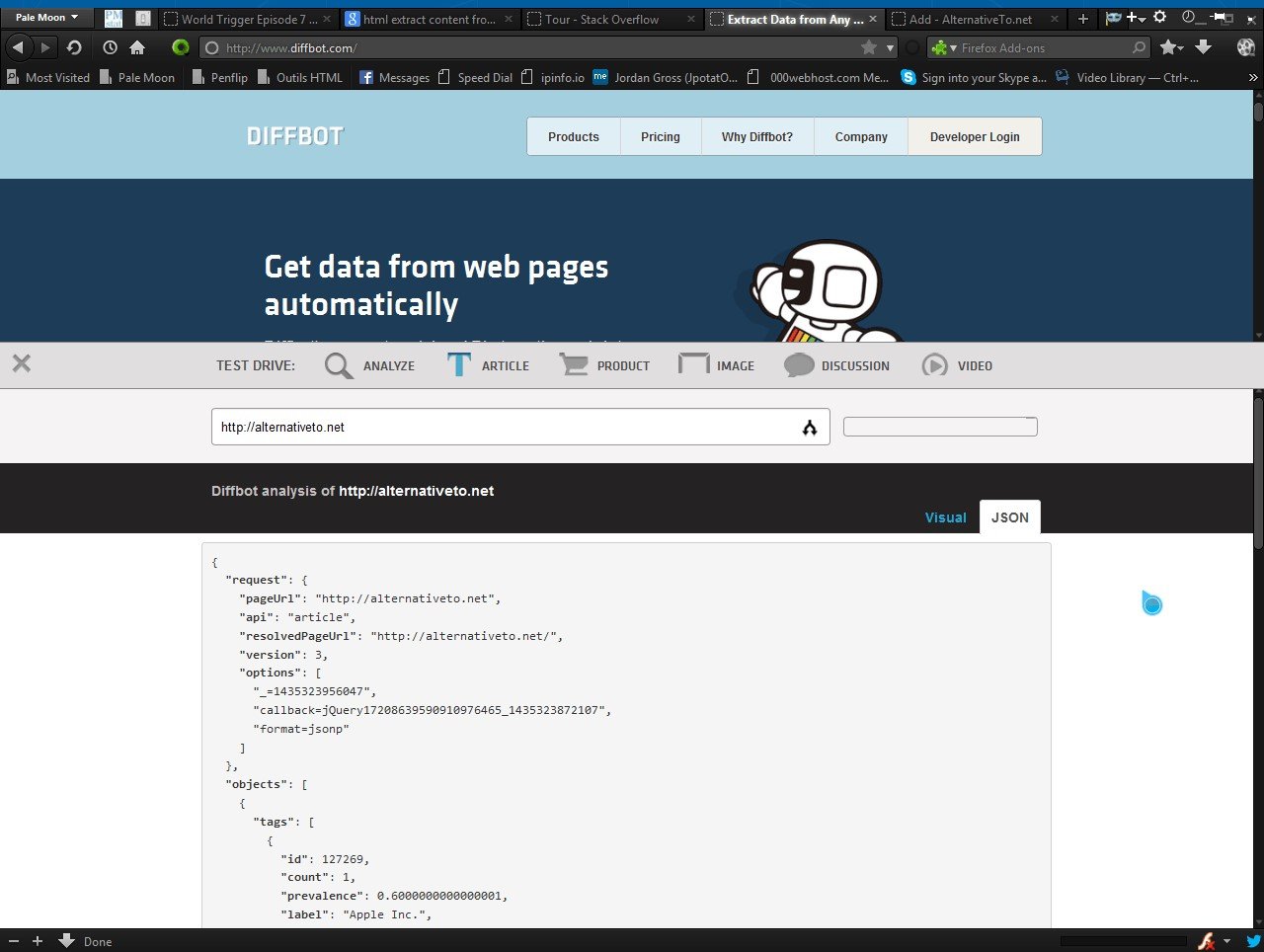
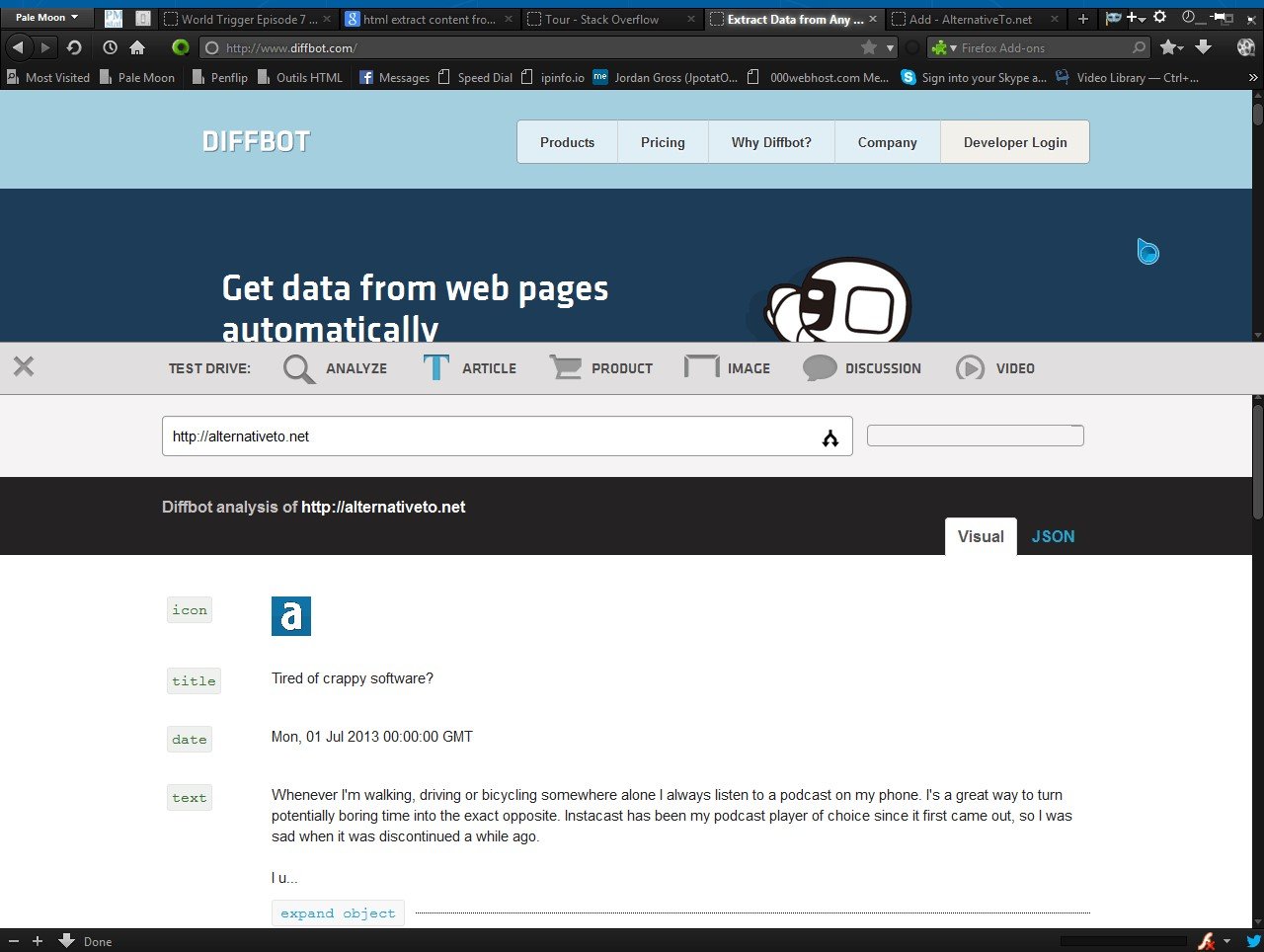
Diffbot działa automatycznie - bez reguł i szkolenia. Nie ma lepszego sposobu na wydobycie danych ze stron internetowych. Zobacz, jak Diffbot kumuluje się z innymi metodami ekstrakcji treści: Porównanie funkcji Ekstrakcja tekstu Jakość zdjęć
#Identyfikuj strony automatycznie:
Użyj interfejsu API Analyze, aby automatycznie znajdować i wyodrębniać wszystkie produkty, artykuły, dyskusje lub obrazy podczas indeksowania dowolnej witryny. Przeanalizuj API
# Szczegółowe dane produktu:
Interfejs API produktu automatycznie zwraca pełne informacje o produkcie, w tym wszystkie dane dotyczące cen, identyfikatory produktów, marki i tabele specyfikacji. API produktu
# Wyczyść tekst i HTML:
Artykuły, wątki dyskusyjne, opisy produktów i podpisy graficzne są zwracane w postaci czystego tekstu i oczyszczonego kodu HTML. Zacznij testować już dziś
# Wyszukiwanie strukturalne:
Przeszukuj ustrukturyzowane treści z dowolnego indeksowania w locie za pomocą naszego interfejsu API wyszukiwania, zwracając tylko pasujące wyniki.
Plus...
¤ Wszystkie interfejsy API wykonują Javascript, więc treść jest analizowana jak zwykła przeglądarka. ¤ Działa na większości stron nieanglojęzycznych dzięki przetwarzaniu wizualnemu. Norm Normalizacja daty: Znaczniki danych są znormalizowane i prezentowane w standardowym formacie RFC 1123 (HTTP / 1.1). Articles Artykuły na wielu stronach są automatycznie łączone razem w jednej odpowiedzi API. Extraction Ekstrakcja encji: automatyczne tagowanie identyfikuje główne tematy i encje w tekście artykułu. ¤ Napraw wszelkie problemy w czasie rzeczywistym za pomocą API Toolkit. ¤ Bulk API pozwala na ekstrakcję setek do setek tysięcy stron. ¤ Dostęp do danych zadania Crawlbot i Bulk w pełnych formatach JSON lub CSV. ¤ Opcjonalnie indeksuj przy użyciu różnorodnej tablicy adresów IP.