Abbiamo compilato una lista di 13 alternative gratuite e a pagamento a reCAPTCHA. I principali concorrenti includono Captcheck, Confident Captcha. Inoltre, gli utenti fanno anche confronti tra reCAPTCHA e phpformmailer, Solve Media's CAPTCHA TYPE-IN™, Sblam!. Puoi anche dare un'occhiata ad altre opzioni simili qui: About.
Abbiamo compilato una lista di 13 alternative gratuite e a pagamento a reCAPTCHA. I principali concorrenti includono Captcheck, Confident Captcha. Inoltre, gli utenti fanno anche confronti tra reCAPTCHA e phpformmailer, Solve Media's CAPTCHA TYPE-IN™, Sblam!. Puoi anche dare un'occhiata ad altre opzioni simili qui: About.
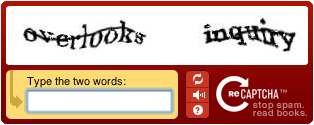
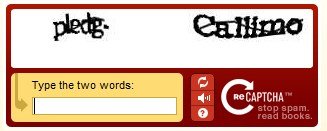
reCAPTCHA è un servizio CAPTCHA gratuito che aiuta a digitalizzare libri, giornali e radio d'epoca ...
reCAPTCHA è un servizio CAPTCHA gratuito che aiuta a digitalizzare libri, giornali e radio d'epoca ...
reCAPTCHA Piattaforme
Web-Based
reCAPTCHA Video e screenshot
reCAPTCHA Panoramica
reCAPTCHA è un servizio CAPTCHA gratuito che aiuta a digitalizzare libri, giornali e programmi radiofonici dei vecchi tempi.
Ogni giorno circa 200 milioni di CAPTCHA vengono risolti dagli umani di tutto il mondo. In ogni caso, si trascorrono circa dieci secondi di tempo umano. Individualmente, non è molto tempo, ma nel complesso questi piccoli puzzle consumano più di 150.000 ore di lavoro ogni giorno. E se potessimo fare un uso positivo di questo sforzo umano? reCAPTCHA fa esattamente questo incanalando lo sforzo speso per risolvere i CAPTCHA online nella "lettura" di libri.
Per archiviare le conoscenze umane e rendere le informazioni più accessibili al mondo, numerosi progetti stanno attualmente digitalizzando libri fisici scritti prima dell'era dei computer. Le pagine del libro vengono scansionate fotograficamente e poi trasformate in testo usando "Riconoscimento ottico dei caratteri" (OCR). La trasformazione in testo è utile perché la scansione di un libro produce immagini, che sono difficili da archiviare su piccoli dispositivi, costose da scaricare e non possono essere cercate. Il problema è che l'OCR non è perfetto.